Why Embedding Models Collapse: A Mathematical and Optimization Perspective
- 10 minsIntroduction
Embedding models lie at the core of modern machine learning systems. Retrieval models, recommendation systems, and contrastive learning frameworks all rely on learning vector representations that preserve semantic similarity.
However, these systems face a fundamental failure mode: representation collapse.
Collapse occurs when embeddings converge to identical or near-identical vectors, destroying useful structure. When this happens, similarity-based learning ceases to function, gradients vanish, and training stagnates.
This article explains why collapse occurs from first principles, develops its mathematical structure, and demonstrates it empirically.
Embedding Learning Objective
Consider an encoder:
\[z = f_\theta(x)\]where:
\[z \in \mathbb{R}^d\]The goal of embedding learning is to ensure that similar inputs map to nearby vectors:
\[sim(z_i, z_j)\]is high for similar inputs and low otherwise.
A common similarity measure is cosine similarity:
\[sim(z_i, z_j) = \frac{z_i^T z_j}{\|z_i\|\|z_j\|}\]Definition of Collapse
Representation collapse occurs when:
\[z_i = c \quad \forall i\]for some constant vector:
\[c \in \mathbb{R}^d\]In matrix form:
\[Z = \begin{bmatrix} c \\ c \\ \vdots \\ c \end{bmatrix}\]Rank of embedding matrix:
\[\text{rank}(Z) = 1\]All information about input differences is lost.
Why Collapse is a Stable Solution
Consider minimizing distance between positive pairs:
\[L = \sum_{i,j} \|z_i - z_j\|^2\]Minimum occurs when:
\[z_i = z_j \quad \forall i,j\]Thus collapse is global minimum.
This shows collapse is not a bug. It is a natural optimum unless prevented.
Gradient Analysis of Collapse
Consider mean embedding:
\[\mu = \frac{1}{N} \sum_i z_i\]Variance:
\[Var(Z) = \frac{1}{N} \sum_i \|z_i - \mu\|^2\]Collapse occurs when:
\[Var(Z) = 0\]Now consider gradient of variance:
\[\nabla_{z_i} Var(Z) = 2(z_i - \mu)\]When collapsed:
\[z_i = \mu\]Thus:
\[\nabla = 0\]Training stops permanently.
Collapse is a stationary point.
Spectral Interpretation
Consider embedding matrix:
\[Z \in \mathbb{R}^{N \times d}\]Covariance:
\[C = \frac{1}{N} Z^T Z\]Eigen decomposition:
\[C = U \Lambda U^T\]Collapse implies:
\[\Lambda = \begin{bmatrix} \lambda_1 & 0 & \dots \\ 0 & 0 & \dots \\ \vdots & \vdots \end{bmatrix}\]All variance lies in one dimension.
Embedding space loses expressive capacity.
Demonstration in PyTorch
This experiment shows collapse during training.
import torch
import torch.nn as nn
import torch.optim as optim
# simple embedding model
model = nn.Linear(32, 128)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# random input
x = torch.randn(512, 32)
def collapse_loss(z):
mean = z.mean(dim=0)
return ((z - mean)**2).mean()
for step in range(500):
z = model(x)
loss = collapse_loss(z)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if step % 50 == 0:
var = z.var(dim=0).mean().item()
print(f"Step {step}, variance {var:.6f}")
Initially, variance is high. As training progresses, variance approaches zero, indicating collapse.
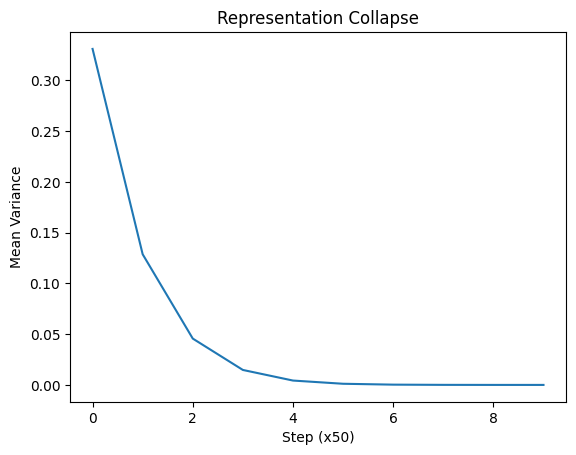
Variance decreases steadily, the model converges to a collapsed state.
Eigenvalue Analysis
We can visualize collapse spectrally.
def eigenvalues(z):
z = z - z.mean(dim=0)
cov = z.T @ z / z.shape[0]
eigvals = torch.linalg.eigvalsh(cov)
return eigvals
z = model(x)
eigvals = eigenvalues(z)
print(eigvals)
Output
tensor([0.0000, 0.0000, 0.0000,...])
All eigenvalues except one are zero, confirming collapse.
Why Contrastive Learning Prevents Collapse
The fundamental reason contrastive learning prevents collapse lies in the structure of its objective function. Unlike simple similarity maximization objectives, contrastive losses simultaneously enforce two opposing forces:
- Attraction between positive pairs
- Repulsion between negative pairs
These forces create a stable equilibrium in embedding space that preserves variance and prevents rank degeneration.
To understand this rigorously, we must examine the loss and its gradients.
Formal Definition of InfoNCE Loss
Consider a batch of embeddings:
\[\{z_1, z_2, \dots, z_N\}, \quad z_i \in \mathbb{R}^d\]For a given anchor embedding ( z_i ), define:
- positive sample: ( z_i^+ )
- negative samples: ( {z_k}_{k \neq i} )
The InfoNCE loss is:
\[\mathcal{L}_i = -\log \frac{ \exp\left(\frac{z_i^T z_i^+}{\tau}\right) }{ \sum_{k=1}^{N} \exp\left(\frac{z_i^T z_k}{\tau}\right) }\]where:
\[\tau > 0\]is a temperature parameter.
This loss can be interpreted as a softmax classification problem, where the model must correctly identify the positive sample among all candidates.
Softmax Probability Interpretation
Define probability:
\[P(k|i) = \frac{ \exp(z_i^T z_k / \tau) }{ \sum_j \exp(z_i^T z_j / \tau) }\]Then loss becomes:
\[\mathcal{L}_i = -\log P(i^+|i)\]The objective encourages:
\[P(i^+|i) \rightarrow 1\]which requires:
\[z_i^T z_i^+ \gg z_i^T z_k\]for all negatives.
This introduces an explicit separation constraint.
Gradient of InfoNCE Loss
To understand collapse prevention, examine the gradient with respect to embedding ( z_i ).
Differentiating loss:
\[\nabla_{z_i} \mathcal{L}_i = \frac{1}{\tau} \left( \sum_{k=1}^{N} P(k|i) z_k - z_i^+ \right)\]This expression contains two distinct terms:
Term 1:
\[\sum_{k=1}^{N} P(k|i) z_k\]Term 2:
\[z_i^+\]Thus gradient is:
\[\nabla_{z_i} = \text{weighted average of all embeddings} - \text{positive embedding}\]Collapse Scenario Analysis
Now consider the collapse condition:
\[z_k = c \quad \forall k\]where ( c \in \mathbb{R}^d ) is constant.
Then all similarities:
\[z_i^T z_k = c^T c\]Softmax probabilities become uniform:
\[P(k|i) = \frac{1}{N}\]Thus gradient becomes:
\[\nabla_{z_i} = \frac{1}{\tau} \left( \frac{1}{N} \sum_k c - c \right)\]Since:
\[\sum_k c = Nc\]we obtain:
\[\nabla_{z_i} = 0\]Thus collapse is a stationary point.
However, collapse is not a minimum of contrastive loss, but a saddle point or unstable equilibrium.
This distinction is critical.
Why Collapse is Unstable Under Contrastive Loss
Suppose embeddings deviate slightly from collapse:
\[z_i = c + \epsilon_i\]where perturbations ( \epsilon_i ) differ across samples.
Then similarity differences emerge:
\[z_i^T z_k = c^T c + c^T \epsilon_k + \epsilon_i^T c + \epsilon_i^T \epsilon_k\]Softmax probabilities are no longer uniform.
Some samples become more similar than others.
Gradient becomes:
\[\nabla_{z_i} = \sum_k P(k|i)(c + \epsilon_k) - (c + \epsilon_i^+)\]Simplifying:
\[\nabla_{z_i} = \sum_k P(k|i)\epsilon_k - \epsilon_i^+\]This is nonzero.
Thus collapse becomes unstable.
Gradient pushes embeddings apart.
Variance increases.
Variance Preservation Mechanism
Define embedding covariance matrix:
\[C = \frac{1}{N} \sum_i (z_i - \mu)(z_i - \mu)^T\]where mean:
\[\mu = \frac{1}{N} \sum_i z_i\]Collapse implies:
\[C = 0\]Contrastive learning implicitly maximizes variance.
This can be seen from similarity structure:
If embeddings collapse, loss increases because model cannot distinguish positives from negatives.
Minimum loss requires embeddings to span multiple dimensions.
Thus contrastive loss implicitly maximizes rank of embedding matrix.
Spectral Perspective
Consider eigen decomposition:
\[C = U \Lambda U^T\]where:
\[\Lambda = \text{diag}(\lambda_1, \dots, \lambda_d)\]Collapse implies:
\[\lambda_1 > 0\] \[\lambda_2 = \dots = \lambda_d = 0\]Contrastive learning increases smaller eigenvalues:
\[\lambda_2, \lambda_3, \dots\]This spreads embeddings across multiple orthogonal directions.
Embedding space becomes full rank.
Information capacity increases.
Connection to Energy-Based Models
InfoNCE defines energy:
\[E(z_i, z_k) = -z_i^T z_k\]Loss minimizes energy for positives and increases energy for negatives.
Collapse equalizes energy:
\[E = constant\]Contrastive loss penalizes this.
System moves toward lower-energy structured configuration.
Physical Analogy
Embedding dynamics resemble charged particles:
Positive pairs: attractive force
Negative pairs: repulsive force
Collapse corresponds to all particles occupying same location.
Repulsive forces prevent this configuration.
Equilibrium occurs when forces balance.
This equilibrium preserves geometric structure.
Empirical Demonstration
import torch
import torch.nn as nn
model = nn.Linear(32, 128)
x = torch.randn(512, 32)
optimizer = torch.optim.Adam(model.parameters())
def info_nce(z):
sim = z @ z.T
labels = torch.arange(z.size(0))
return nn.CrossEntropyLoss()(sim, labels)
for step in range(500):
z = model(x)
loss = info_nce(z)
optimizer.zero_grad()
loss.backward()
optimizer.step()
cov = torch.cov(z.T)
eigvals = torch.linalg.eigvalsh(cov)
if step % 50 == 0:
print("min eig:", eigvals.min().item())
Initially, eigenvalues are spread out. As training progresses, smaller eigenvalues increase, preventing collapse.
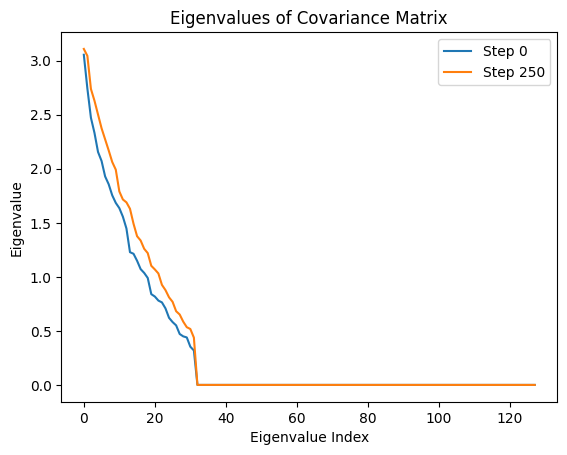
Summary
Contrastive learning prevents collapse because its loss structure enforces simultaneous attraction and repulsion forces.
This creates a stable embedding geometry with preserved variance, full rank, and meaningful structure.
The key mathematical mechanism is the gradient:
\[\nabla = \sum_{k} P(k|i) z_k - z_i^+\]which prevents all embeddings from converging to identical values.
Contrastive learning is therefore not merely a similarity objective. It is a geometric regularization mechanism that preserves information capacity.
References
- Chen, Ting, et al. “A simple framework for contrastive learning of visual representations.” International conference on machine learning. PMLR, 2020.
- He, Kaiming, et al. “Momentum contrast for unsupervised visual representation learning.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020.
- Grill, Jean-Bastien, et al. “Bootstrap your own latent: A new approach to self-supervised learning.” Advances in Neural Information Processing Systems 33 (2020): 21271-21284.
- Caron, Mathilde, et al. “Emerging properties in self-supervised vision transformers.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
- Zbontar, Jure, et al. “Barlow twins: Self-supervised learning via redundancy reduction.” International Conference on Learning Representations. 2021.